皆様こんにちは,同志社大学の土屋誠司です.人工知能の第30回目の今回は,前回に引き続き,物事を分類する手法であるサポートベクターマシンについて書いてみたいと思います.
『サポートベクターマシン(Support Vector Machine:SVM)』は,2つのクラスに分類するパターン識別器として最も有名で広く用いられている技術です.あるパターンを識別するためには,人間と同じように,その種類や特徴をあらかじめ学習しておく必要があります.学習の際に用いる入力データに対する答えとなるデータを『教師データ』と呼びます.この入力データと教師データのセットを訓練データと呼び,パターンを識別する学習を行うときに利用します.また,正しく学習できたかどうかを評価する必要もあります.これも人間がテストを受けるのと同じです.この学習結果を評価する際に用いるデータを『テストデータ』と呼びます.
SVMでは,ある物事を2つのクラスに分類することになりますが,これは,入力データを教師データに合うように2つに分類する境界を求めることになります.その際,各入力データと境界との距離がなるべく離れるように境界線を引いていきます.こうすることで,汎化性能を担保することができます.
SVMでは,下の図のように曲線を使って物事を分けるだけではなく,直線で分けることももちろんできます.直線で境界線を描く分類方法を『線形分類』,曲線で境界線を描く分類方法を『非線形分類』と呼びます.
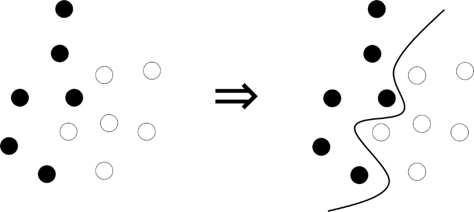
図 SVMのイメージ図
なお,訓練データを正しく解答できるように学習する時,あまり学習し過ぎるとその訓練データは正しく解答することはできるのですが,少し違った他のデータにはうまく対応できなくなってしまうことがあります.この現象のことを『過学習』と呼び,こうならないように注意する必要があります.これも人間とまったく同じです.あまりに勉強し過ぎると,また勉強だけしていてもダメですよね.
次回は,昨今の第三次人工知能ブームで注目されている機械学習として,ディープラーニングとニューラルネットワークについて書いてみたいと思います.
